Data Encoding Techniques
Introduction
In order to transport digital bits of data across carrier waves, encoding techniques have been developed each with
their own pros and cons. This document briefly describes some of the more common techniques.
Character Coding Techniques
Baudot
Jean-Maurice-Emile Baudot developed a character set in 1874 that used series of bits to represent characters that could be sent
over a telegraph wire or radio signal. A 5-key keyboard was developed to implement this Baudot code that was modified by
Donald Murray in 1901 and it became the International Telegraph Alphabet 1 (ITA1) and then developed into ITA2.
ITA2 was the coding that was actually implemented on equipment. Characters such as Line Feed (LF) were given a 5 bit
code such as 00010.
The problem with using 5 bits for each character is that there is a limitation on the number of characters that can
be generated from them, 25 gives 32 different combinations. This may be fine for 26 letters of the English
alphabet but it is not enough to cover punctuation or control characters. Other coding techniques were needed.
Binary Coded Decimal (BCD)
BCD uses a series of 4 bits called a nibble to represent a decimal number, as the following table demonstrates:
| Decimal |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
| BCD |
0000 |
0001 |
0010 |
0011 |
0100 |
0101 |
0110 |
0111 |
1000 |
1001 |
So for example, the number 1456 would be represented by 0001 0100 0101 0110. This makes it easier
to convert numbers and for displays, however the electronics required in calculations is quite complex.
American Standard Code for Information Interchange (ASCII)
Originally published in 1963, ASCII is based on 7 bits to represent English characters and
after a number of revisions ASCII now supports 95 printable characters and 33 control
characters (a total of 2 7 = 128). ASCII is the americanised vsersion of that defined by CCITT in ISO 646 and is
known as the International Alphabet 5 (IA5).
The first 32 characters are control characters and are represented by the 7-bit codes 000 0000 (null character)
through to 001 1111 (unit separator). The 128th control character is 'delete' represented by 111 1111.
The rest of the characters are printable and the coding caters for both lower and uppercase english letters e.g.
the letter 'd' is represented by 110 0100 whereas its upper case equivalent is represented by 100 0100.
Extended Binary Coded Decimal Interchange Code (EBCDIC)
Around the same time that ASCII was developed, in 1964 IBM produced EBCDIC which is an 8-bit coding system
designed to replace BCD within its computer systems. An EBCDIC byte is divided in two nibbles. The first four bits
is called the zone and this represents the category of the character, the last four bits is called the digit
and this identifies the specific character.
Different countries adapted EBCDIC for their own alphabets. The Chinese had a double byte extension that allowed them
to display Chinese characters. IBM numbered the different character sets with Coded Character Set Identifier (CCSID)
of which there are many around the world.
Unicode
Originally published in 1991 by the Unicode Consortium as Unicode 1.0 (in 2006 Unicode 5.0 was released),
Unicode aims to provide a means for the traditional
character sets around the world to take part in multilingual computer processing amongst themselves rather than have to translate
into a Roman character set first.
The bit patterns of the 95 printable ASCII characters are sufficient to exchange information in modern English, however
many languages that use the Latin alphabet need additional symbols not covered by ASCII. ISO/IEC 8859 attempts to address
this by utilising the eighth bit in an 8-bit byte in order to allow positions for another 128 characters.
This bit was previously used for data transmission protocol information, or was left unused. Even more characters
were needed than could fit in a single 8-bit character encoding, so several mappings were developed.
ISO/IEC 8859 comes in parts and these are given a number e.g. ISO 8859-15.
Unicode creates codes for the characters or basic graphical representation of the character (called a 'grapheme').
The first 256 code points have been reserved for ISO 5589-1 in order to make it straightforward to convert the
Roman text. There are two Unicode mapping methods; Unicode Transformation Format (UTF) and
Unicode Character Set (UCS). An encoding maps the range of Unicode code points to sequences of values
in a fixed-size range of code values. The numbers in the names of the encodings indicate the number of bits
in one code value (for UTF encodings) or the number of bytes per code value (for UCS) encodings.
UCS assigns a code per character. UCS-2 uses two bytes per character, UCS-4
uses 4 bytes per character.
Some Unicode examples:
- UTF-7 � a 7-bit encoding, often considered obsolete (not part of Unicode but rather an RFC)
- UTF-8 � an 8-bit, variable-width encoding, which maximizes compatibility with ASCII. In common use
and is in fact a superset of ASCII. The IMC and IETF use UTF-8 when determining standards for supporting
email and Internet traffic.
- UTF-EBCDIC � an 8-bit variable-width encoding, which maximizes compatibility with EBCDIC. (not
part of Unicode)
- UTF-16 � a 16-bit, variable-width encoding. In common use.
- UTF-32 � a 32-bit, fixed-width encoding
Manchester Phase Encoding (MPE)
802.3 Ethernet uses Manchester Phase Encoding (MPE). A data bit '1'
from the level-encoded signal (i.e. that from the digital circuitry in the host machine
sending data) is represented by a full cycle of the inverted signal from the master clock which matches with the '0' to '1' rise
of the phase-encoded signal (linked to the phase of the carrier signal which goes out on the wire).
i.e. -V in the first half of the signal and +V in the second half.
The data bit '0' from the level-encoded signal is represented by a full normal cycle of
the master clock which gives the '1' to '0' fall of the phase-encoded signal.
i.e. +V in the first half of the signal and -V in the second half.

The above diagram shows graphically how MPE operates. The example at the bottom of the diagram indicates how the digital
bit stream 10110 is encoded.
A transition in the middle of each bit makes it possible to synchronize the sender and receiver.
At any instant the ether can be in one of three states: transmitting a 0 bit (-0.85v),
transmitting a 1 bit (0.85v) or idle (0 volts). Having a normal clock signal as well as an inverted clock signal
leads to regular transitions which means that synchronisation of clocks is easily achieved even if there are a series of
'0's or '1's. This results in highly reliable data transmission.
The master clock speed for Manchester encoding always matches the data speed
and this determines the carrier signal frequency, so for 10Mbps Ethernet the carrier is 10MHz.
Differential Manchester Encoding (DME)
A '1' bit is indicated by making the first half of the signal, equal to the last half of the previous bit's
signal i.e. no transition at the start of the bit-time.
A '0' bit is indicated by making the first half of the signal opposite to the last half of the previous
bit's signal i.e. a zero bit is indicated by a transition at the beginning of the bit-time.
In the middle of the bit-time there is always a transition, whether from high to low, or low to high.
Each bit transmitted means a voltage change always occurs in the middle of the bit-time to ensure clock synchronisation.
Token Ring uses DME and
this is why a preamble is not required in Token Ring, compared to Ethernet which uses Manchester encoding.
Non Return to Zero (NRZ)
NRZ encoding uses 0 volts for a data bit of '0' and a +V volts for a data bit of '1'.
The problem with this is that it is difficult to distinguish a series of '1's or '0's due to
clock synchronisation issues. Also, the average DC voltage is 1/2V so there is high power output.
In addition, the bandwidth is large i.e. from 0Hz to half the data rate because for every full signal wave,
two bits of data can be transmitted (remember that with MPE the data rate equals the bit rate which is even
more inefficient!) i.e. two bits of information are transmitted for every cycle (or hertz).
After 50m of cable attenuation the signal amplitude may have been reduced to
100mV giving an induced noise tolerance of 100mV.
Return to Zero (RZ)
With RZ a '0' bit is represented by 0 volts whereas a '1' data bit is represented by +V volts for half the cycle and
0 volts for the second half of the cycle. This means that the average DC voltage is reduced to 1/4V plus there is the
added benefit of there always being a voltage change even if there are a series of '1's. Unfortunately, the efficiency
of bandwidth usage decreases if there are a series of '1's since now a '1' uses a whole cycle.
Non Return to Zero Invertive (NRZ-I)
With NRZ-I a '1' bit is represented by 0 volts or +V volts depending
on the previous level. If the previous voltage was 0 volts then the '1' bit will be represented by +V volts, however
if the previous voltage was +V volts then the '1' bit will be represented by 0 volts. A '0' bit is represented by
whatever voltage level was used previously. This means that only a '1' bit can 'invert' the voltage, a '0' bit
has no effect on the voltage, it remains the same as the previous bit whatever that voltage was.
This can be demonstrated in the following examples for the binary patterns 10110 and 11111:
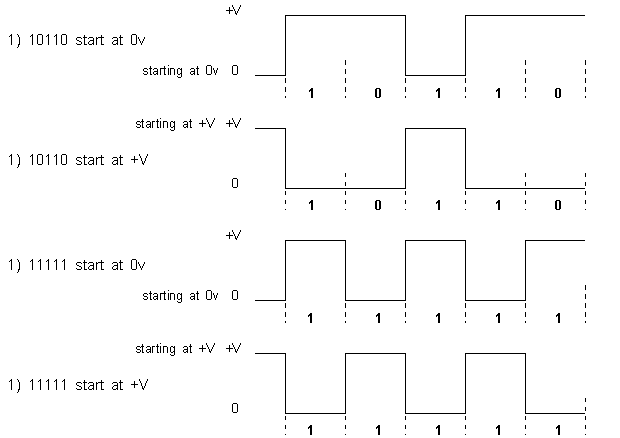
Note how that a '1' inverts the voltage whilst a '0' leaves it where it is. This means that the encoding is different
for the same binary pattern depending on the voltage starting point.
The bandwidth usage is minimised with NRZ-I, plus there are frequent voltage changes required for clock synchronisation.
With fibre there are no issues with power output so a higher clock frequency is fine whereas with copper NRZ-I would not
be acceptable.
4B/5B
4B/5B encoding is sometimes called 'Block coding'.
To get around this problem, an intermediate encoding takes place before the MLT-3 encoding. Each 4-bit 'nibble' of
received data has an extra 5th bit added. If input data is dealt with in 4-bit nibbles there are 24 = 16
different bit patterns. With 5-bit 'packets' there are 25 = 32 different bit patterns. As a result, the 5-bit
patterns can always have two '1's in them even if the data is all '0's a translation occurs to another of the bit patterns.
This enables clock synchronisations required for reliable data transfer.
Notice that the clock frequency is 125MHz. The reason for this is due to the 4B/5B encoding. A 100MHz signal would not have
been enough to give us 100Mbps, we need a 125MHz clock.
5B/6B
Same idea as 4B/5B but you can have DC balance (3 zero bits and 3 one bits in each group of 6) to prevent
polarisation. 5B/6B Encoding is the process of encoding the scrambled 5-bit data patterns into
predetermined 6-bit symbols.
This creates a balanced data pattern, containing equal numbers of 0's and 1's, to provide guaranteed
clock transitions synchronization for receiver circuitry, as well as an even power value on the line.
5B6B encoding also provides an added error-checking capability. Invalid symbols and invalid data patterns, such
as more than three 0's or three 1's in a row, are easily detected
For 100VG-AnyLAN for instance, the clock rate on each wire is 30MHz, therefore 30Mbits per second are
transmitted on each pair giving a total data rate of 120Mbits/sec. Since each 6-bits of data on the line
represents 5 bits of real data due to the 5B/6B encoding, the rate of real data being transmitted is 25Mbits/sec
on each pair, giving a total rate of real data of 100Mbits/sec. For 2-pair STP and fiber, the data rate is
120Mbits/sec on the transmitting pair, for a real data transmission rate of 100Mbits/sec.
8B/6T
8B/6T means send 8 data bits as six ternary (one of three voltage levels) signals. 3/4 (6/8) wave transitions transitions per bit
i.e. the carrier just needs to be running at 3/4 of the speed of the data rate.
The incoming data stream is split into 8-bit patterns.
Each 8-bit data pattern with two voltage levels 0 volts and V volts is examined. This 8-bit pattern is then
converted into a 6-bit pattern but using three voltage levels -V, 0 and V volts, so each 8-bit pattern has
a unique 6T code. For example the bit pattern 0000 0000 (0x00) uses the code +-00+-
and 0000 1110 (0x)E) uses the code -+0-0+. There are 36 = 729
possible patterns (symbols). The rules for the symbols are that there must be at least two voltage transitions
(to maintain clock synchronisation) and the average DC voltage must be zero (this is called 'DC balance' that is the overall
DC voltage is summed up to 0v, the +V and -V transitions are evenly balanced either side of 0V)
which stops any polarisation on the cable.
The maximum frequency that the 6T codes could generate on one carrier is 37.5MHz. FCC rules do not allow anything above
30MHz on cables and Category 3 cable does not allow anything above 16MHz (which is what 100BaseT4 was designed for).
The 100BaseT4 standard uses 8B/6T encoding on three pairs in a round robin fashion such that the maximum carrier frequency
on any single pair is 37.5/3 = 12.5MHz.
8B/10B
Each octet of data is examined and assigned a 10 bit code group. The data octet is split up into the 3 most
significant bits and the 5 least significant bits. This is then represented as two decimal numbers with
the least significant bits first e.g. for the octet 101 00110 we get the decimal 6.5. 10 bits are
used to create this code group and the naming convention follows the format /D6.5/.
There are also 12 special code groups which follow the naming convention /Kx.y/.
The 10 bit code groups must either contain five ones and five zeros, or four ones and six zeros, or six ones
and four zeros. This ensures that not too many consecutive ones and zeros occurs between code groups thereby maintaining
clock synchronisation. Two 'commas' are used to aid in bit synchronisation, these 'commas' are the 7 bit patterns
0011111 (+comma)and 1100000 (-comma).
In order to maintain a DC balance, a calculation called the Running Disparity calculation is used to try to
keep the number of '0's transmitted the same as the number of '1's transmitted.
This uses 10 bits for each 8 bits of data and therefore drops the data rate speed relative to the line speed,
for instance in order to gain a data rate of 1Gbps the line peed has to be 10/8 x 1 = 1.25Gbps .
MLT-3
This scheme was specified by ANSI X3T9.5 committee. It is used by FDDI and TP-PMD to obtain
100MB/s out of a 31.25MHz signal.
UTP is low pass in nature, meaning that it hinders high frequency signal (like a low-pass filter). So it is not
feasible to merely increase the clock frequency by 10 to 100MHz and use Manchester encoding to give us 100Mbps.
In addition, the FCC (Federal Communications Commission) have severely curtailed the power that is allowed to be
emitted above 30MHz. We have to use another encoding technique in order to transmit high data rates across UTP.
If you take an averaging spectrum analyser and look at the output signal of the 10Mbps Ethernet phase-encoded signal,
you will see a power peak at 10MHz where there is a stream of '1's or '0's, you will see a smaller harmonic at 30MHz and if
there is a stream of '1's and '0's, you will see a peak at 5MHz. Now 100BaseT uses a master clock running at 125MHz instead of 10MHz.
The equivalent peaks would then be at 125MHz, 375MHz and 62.5MHz. Transmission electronics designed to work within the
FCC rules will block the frequencies higher than 30MHz.
To get around this issue we need to concentrate the signal power below 30MHz if possible. To do this the
encoding method Multi-Level Transition 3 (MLT-3) is used. This involves using the pattern 1, 0, -1, 0.
If the next data signal is a '1' then the output 'transitions' to the next bit in the pattern e.g. if the last output bit
was a '-1', and the input bit is a '1', then the next output bit is a '0'. If the next data signal is a '0' then there is no
transition which means that the next output bit is the same as last time, in our case a '0'.
The cycle length of the output signal is therefore going to be 1/4 that of the MPE method so that instead of the main signal peak
being at 125MHz as measured by the averaging spectrum analyser, it will be at 31.25MHz which is near enough to be OK as far
as FCC are concerned. 5 bits are transmitted for every 4 bits of data so that the data bit rate is actually 125Mb/s for
100Mb/s data throughput.
There is an issue with this in that you can end up with a series of '0's or '1's which force the local circuitry to count
the bits using its own free running clock rather than have the check of the clock synchronisation from the transmit
source.
PAM-5
This employs multi-level amplitude signalling.
To encode 8 bits, 28 = 256 codes or symbols, are required since there are 256 possible pattern combinations.
A five level signal (e.g. -2v, -1v, 0v, 1v and 2v) called
Pulse Amplitude Modulation 5 is used (This works in a similar manner to MLT-3).
Bearing in mind that there are 4 separate pairs being used for
transmission and reception of data, this gives us a possibility of 54 = 625 codes to choose from
when using all four pairs. Actually only four levels are used for data, the fifth level (0v) is used for the 4-dimensional
8-state Trellis Forward Error Correction used to recover the transmitted signal from the high noise.
If you plot time (nanoseconds) against voltage you will see an 'eye pattern' effect showing the different signal
levels. Comparing a plot for MLT-3 against PAM-5 will demonstrate how that the separate levels for PAM-5 are
less discreet. This is why extra convolution coding is used called Trellis coding, which uses Viterbi decoding for
error detection and correction.
2 bits are represented per symbol and
the symbol rate is 125Mbps in each direction on a pair because the clock rate is set at 125MHz.
This gives 250Mbps data per pair and therefore 1000Mbps for the whole cable.

This type of encoding is used by Gigabit Ethernet. The data signals have distinct and measurable
amplitude and phases relative to a 'marker signal'. Using this two way matrix allows more
data bits per cycle, in the case of Gigabit Ethernet 1000Mbps is squeezed into 125MHz signals.
The electronics are more complex and the technology is more susceptible to noise.
Feedback Shift Register (FSR)
There is an issue with some encoding schemes of the power of the higher frequency harmonics. To minimise these there is another small
step before wave shaping such as MLT-3 encoding. This step uses a Feedback Shift Register (FSR) to produce a 'pseudo-random' bit pattern
which is Exclusive-ORed with the data stream. This pseudo random stream is a known quantity and is reversed at the other
end by another Excusive-OR operation using the same known pseudo-random bit pattern. The purpose of the randomness
is to reduce the regularity of the signal frequency and consequently the harmonics. The FSR used in 100BaseT
is an 11-bit register that shifts one bit at a time from bit 0 to bit 10 on each clock cycle.

|
